
12 reasons to level-up your team with a delivery playbook
Just like a sports team or an elite operations unit, even engineering teams need a playbook. It's the secret to reliable, repeatable delivery. Here's 12 reasons to use a playbook.
Prioritize customer value from ideation through realization.
Create high-functioning teams obsessed about exceeding customer expectations. Build insight and intelligence, expose gaps, and execute with precision.

Build your business case to identify, protect and realize customer value. No customer misunderstandings or disappointments.
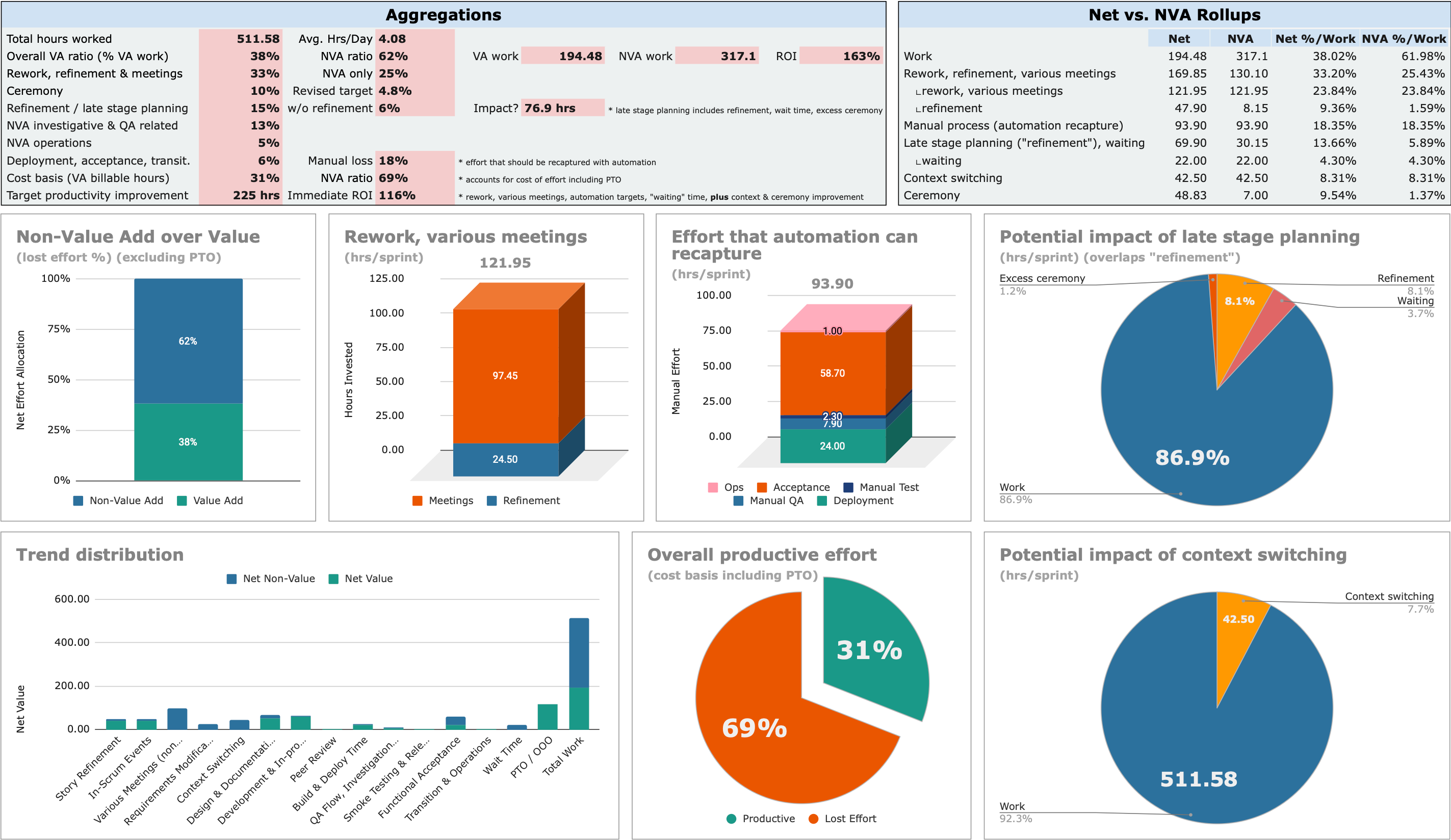
Better insight, better outcomes
In just one sprint give your team the proven accelerators they need to get more done, faster, so they can focus on the customer.

Even engineering teams need a playbook, just like a sports league or an elite operations unit. Build your playbook on a mature, proven foundation.
Deliver faster
Deliver with confidence. Put attention where it belongs, on creating value, security, reliability, and responsiveness from ideation to delivery.
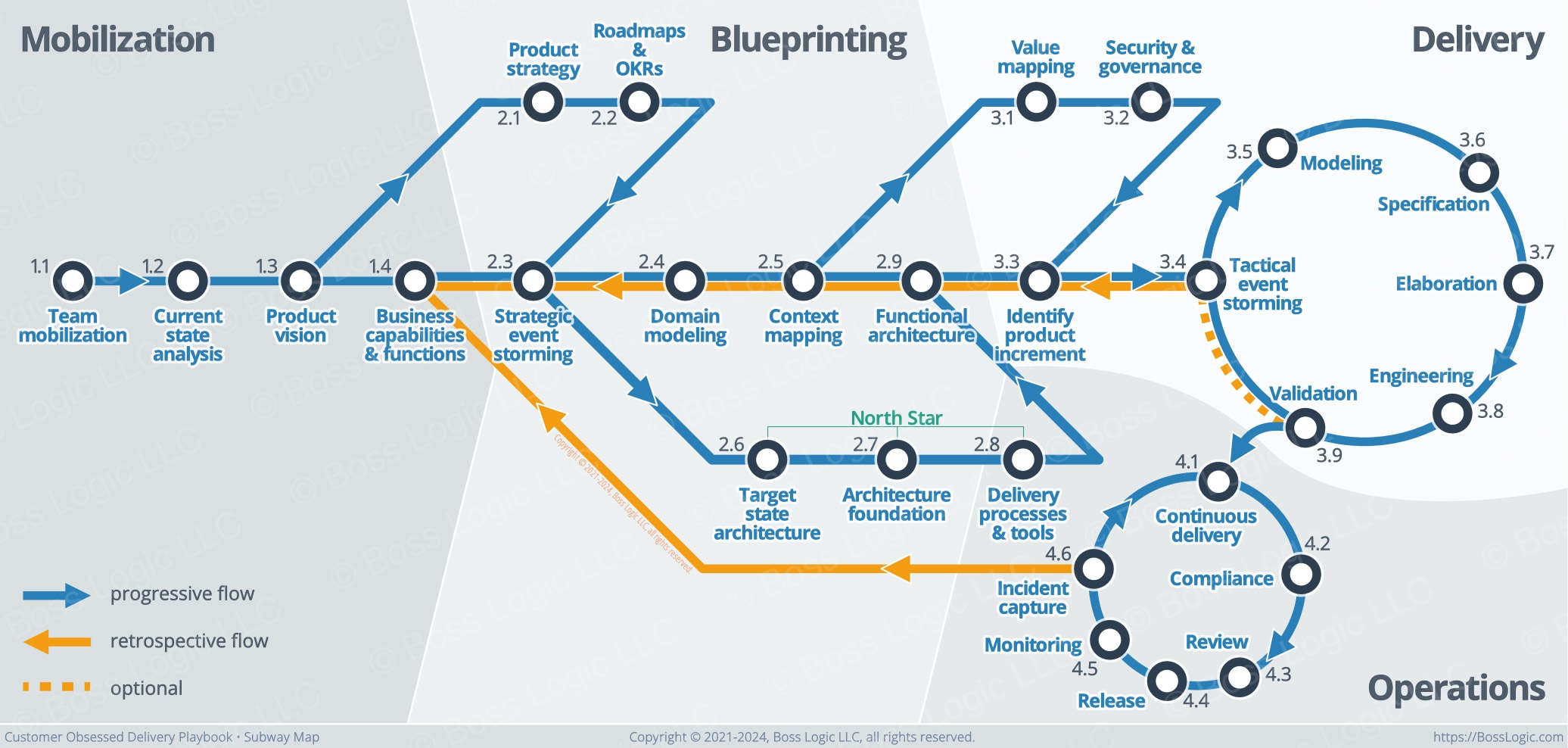
Your playbook is essential. It gives you an edge most teams don’t have. Let's get started on your customer obsessed journey.





Chapter 2.2: We have to empirically measure progress toward success. "Features delivered" is old hat. Create customer-facing value every single time by knowing what to measure and how to keep measuring.
Just like a sports team or an elite operations unit, even engineering teams need a playbook. It's the secret to reliable, repeatable delivery. Here's 12 reasons to use a playbook.

What if every day you made a 1% quality of life improvement to your team's way of working? After a year, you'd be performing at a multiple of 37X.

The upsurge in AI tools is changing software development. But is it for the better, or the worse? This detailed plan makes sure your team, your Delivery Playbook, and your SDLC pipeline are ready.
Get the latest thought leadership on customer obsessed engineering and software development.